Frequently asked questions
⦾ Why is the provisioning status of the target servers stuck at ‘installing’ in cluster.nodeinfo (omniadb)?
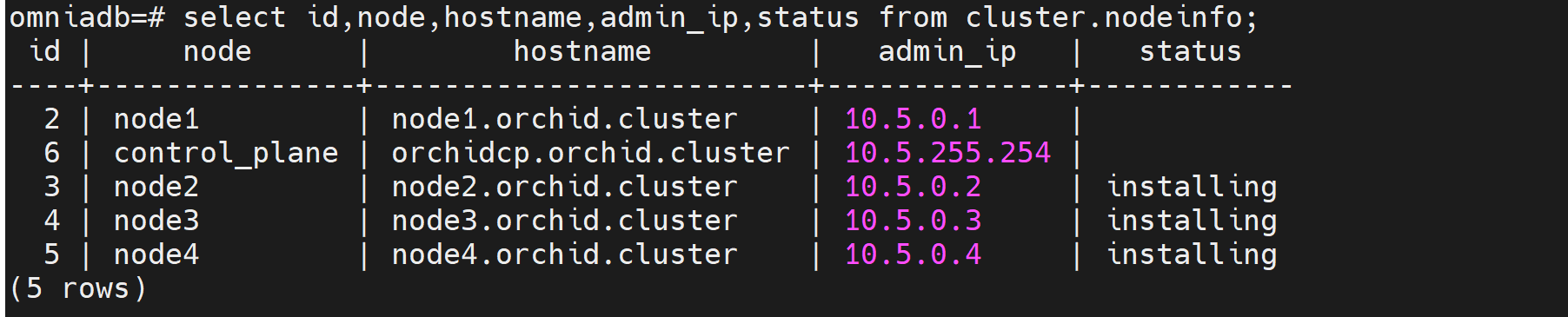

Potential Causes:
Disk partition may not have enough storage space per the requirements specified in
input/provision_config(underdisk_partition)The provided ISO may be corrupt/incomplete.
Hardware issues (Auto reboot may fail at POST)
A virtual disk may not be created
Resolution:
Add more space to the server or modify the requirements specified in
input/provision_config(underdisk_partition)Download the ISO again, verify the checksum/ download size and re-run the provision tool.
Resolve/replace the faulty hardware and PXE boot the node.
Create a virtual disk and PXE boot the node.
⦾ Why is the provisioning status of my target servers stuck at ‘powering-on’ in the cluster.info (omniadb)?
Potential Cause:
Hardware issues (Auto-reboot may fail due to hardware tests failing)
The target node may already have an OS and the first boot PXE device is not configured correctly.
Resolution:
Resolve/replace the faulty hardware and PXE boot the node.
Target servers should be configured to boot in PXE mode with the appropriate NIC as the first boot device.
⦾ What to do if PXE boot fails while discovering target nodes via switch_based discovery with provisioning status stuck at ‘powering-on’ in cluster.nodeinfo (omniadb):

Rectify any probable causes like incorrect/unavailable credentials (
switch_snmp3_usernameandswitch_snmp3_passwordprovided ininput/provision_config.yml), network glitches or incorrect switch IP/port details.Run the clean up script by:
cd utils ansible-playbook control_plane_cleanup.yml
Re-run the provision tool (
ansible-playbook provision.yml).
⦾ What to do if playbook execution fails due to external (network, hardware etc) failure:
Re-run the playbook whose execution failed once the issue is resolved.
⦾ Why don’t IPA commands work after setting up FreeIPA on the cluster?
Potential Cause:
Kerberos authentication may be missing on the target node.
Resolution:
Run
kinit adminon the node and provide thekerberos_admin_passwordwhen prompted. (This password is also entered ininput/security_config.yml.)
⦾ Why are the status and admin_mac fields not populated for specific target nodes in the cluster.nodeinfo table?
Causes:
Nodes do not have their first PXE device set as designated active NIC for PXE booting.
Nodes that have been discovered via SNMP or mapping file have not been PXE booted.
Resolution:
Configure the first PXE device to be active for PXE booting.
PXE boot the target node manually.
⦾ Why does the provision.yml fail at ‘provision validation: Install common packages for provision’ on RHEL nodes running 8.5 or earlier?

- Potential Cause:
sshpass is not available in any of the repositories on the control plane.
Resolution:
Enable RedHat subscription or ensure that sshpass is available to install or download to the control plane (from any local repository).
Note
This error can also take place when task cluster_preperation : Install sshpass is executed during omnia.yml.
⦾ What to do if user login fails when accessing a cluster node:
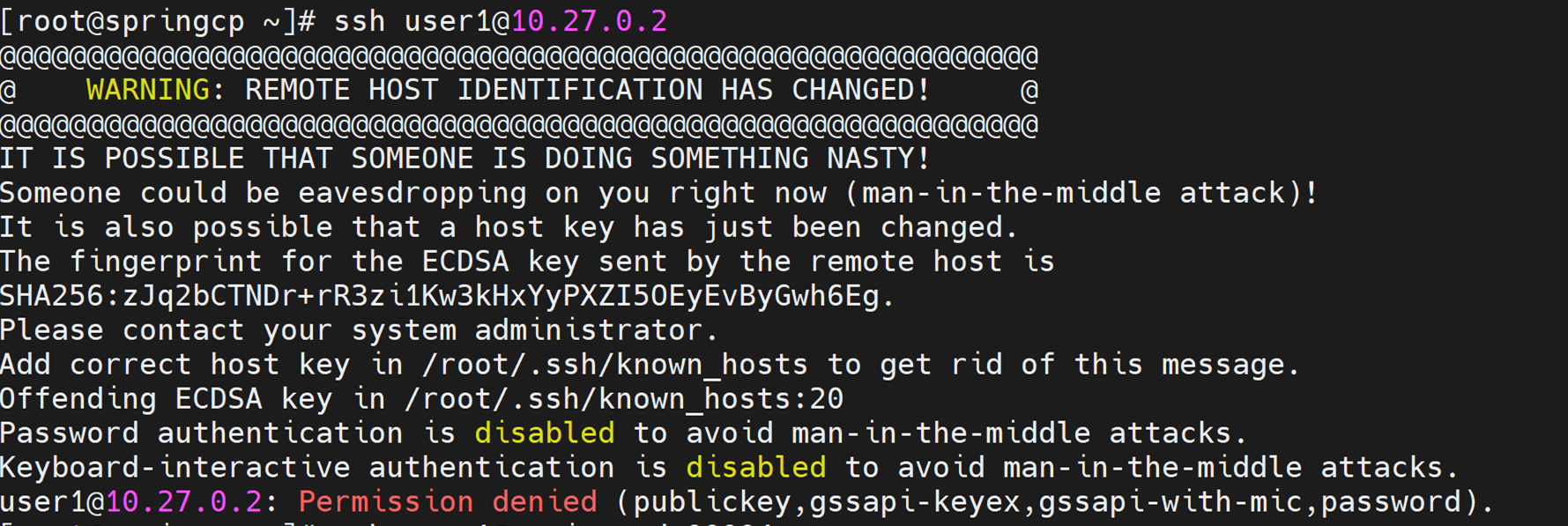
- Potential Cause:
ssh key on the control plane may be outdated.
Resolution:
Refresh the key using
ssh-keygen -R <hostname/server IP>.Retry login.
⦾ Why does the ‘Fail if LDAP home directory exists’ task fail during user_passwordless_ssh.yml?
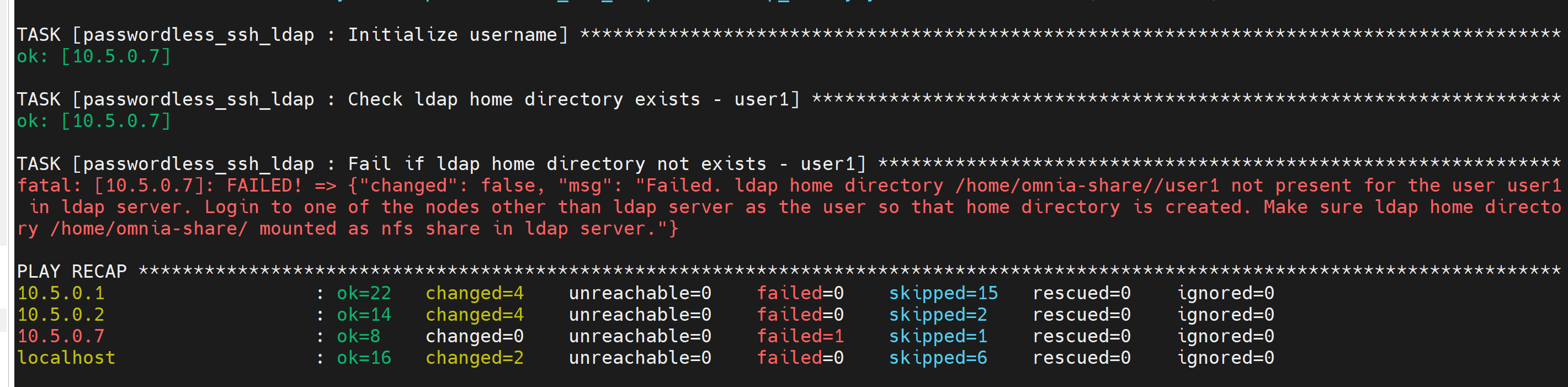
Potential Cause: The required NFS share is not set up on the control plane.
Resolution:
- If
enable_omnia_nfsis true ininput/omnia_config.yml, follow the below steps to configure an NFS share on your LDAP server: - From the manager node:
Add the LDAP server IP address to
/etc/exports.Run
exportfs -rato enable the NFS configuration.
- From the LDAP server:
Add the required fstab entries in
/etc/fstab(The corresponding entry will be available on the compute nodes in/etc/fstab)Mount the NFS share using
mount manager_ip: /home/omnia-share /home/omnia-share
⦾ Why does the ‘Import SCP from a local path’ task fail during idrac.yml?

Potential Cause: The target server may be hung during the booting process.
Resolution: Bring the target node up and re-run the script.
⦾ Why does the ‘Verify primary_dns is reachable’ task fail during provision.yml?

Currently, the primary_dns value stored in input/provision_config.yml cannot be part of any of the subnets (admin_nic_subnet, ib_nic_subnet and bmc_nic_subnet) also defined in input/provision_config.yml.
Ex: If the primary_dns is set to 10.15.0.7, the subnet 10.15.0.0 cannot be used for admin_nic_subnet, ib_nic_subnet or bmc_nic_subnet.
⦾ Why is the node status stuck at ‘powering-on’ or ‘powering-off’ after a control plane reboot?
Potential Cause: The nodes were powering off or powering on during the control plane reboot/shutdown.
Resolution: In the case of a planned shutdown, ensure that the control plane is shut down after the compute nodes. When powering back up, the control plane should be powered on and xCAT services resumed before bringing up the compute nodes. In short, have the control plane as the first node up and the last node down.
For more information, click here
⦾ Why do subscription errors occur on RHEL control planes when rhel_repo_local_path (in input/provision_config.yml) is not provided & control plane does not have an active subscription?

For many of Omnia’s features to work, RHEL control planes need access to the following repositories:
AppStream
BaseOS
CRB
This can only be achieved using local repos specified in rhel_repo_local_path (input/provision_config.yml) OR having an active, available RedHat subscription.
Note
To enable the repositories, run the following commands:
subscription-manager repos --enable=codeready-builder-for-rhel-8-x86_64-rpms
subscription-manager repos --enable=rhel-8-for-x86_64-appstream-rpms
subscription-manager repos --enable=rhel-8-for-x86_64-baseos-rpms
Verify your changes by running:
yum repolist enabled
⦾ Why does the task: Initiate reposync of AppStream, BaseOS and CRB fail?

Potential Cause: The repo_url, repo_name or repo provided in rhel_repo_local_path (input/provision_config.yml) may not be valid.
Omnia does not validate the input of rhel_repo_local_path.
Resolution: Ensure the correct values are passed before re-running provision.yml.
⦾ How to add a new node for provisioning
Using a mapping file:
Update the existing mapping file by appending the new entry (without the disrupting the older entries) or provide a new mapping file by pointing
pxe_mapping_file_pathinprovision_config.ymlto the new location.Run
provision.yml.
Using the switch IP:
Run
provision.ymlonce the switch has discovered the potential new node.
⦾ Why does the task: ‘BeeGFS: Rebuilding BeeGFS client module’ fail?
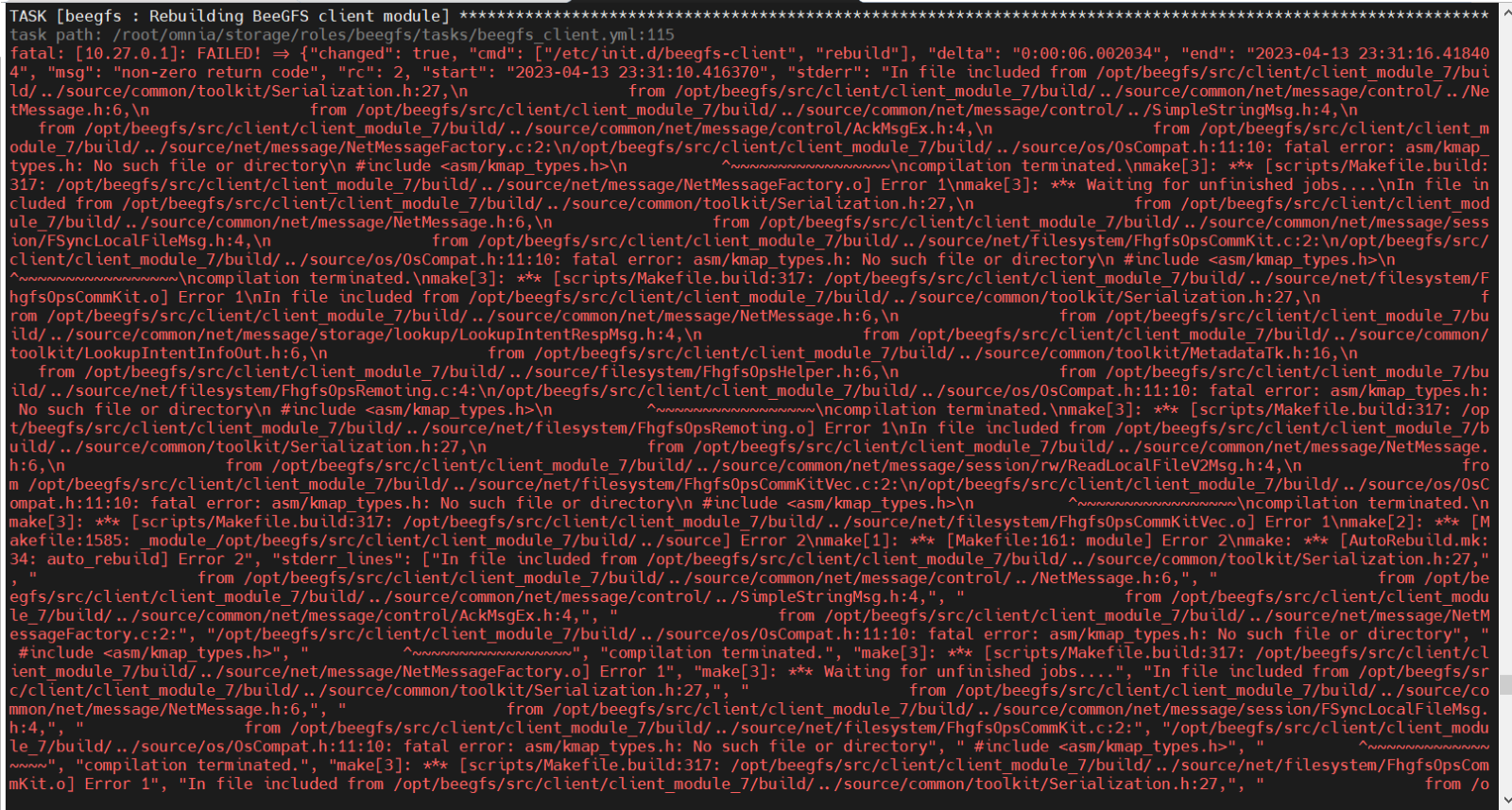
Potential Cause: BeeGFS version 7.3.0 is in use.
Resolution: Use BeeGFS client version 7.3.1 when setting up BeeGFS on the cluster.
⦾ Why does splitting an ethernet Z series port fail with “Failed. Either port already split with different breakout value or port is not available on ethernet switch”?
Potential Cause:
The port is already split.
It is an even-numbered port.
Resolution:
Changing the
breakout_valueon a split port is currently not supported. Ensure the port is un-split before assigning a newbreakout_value.
⦾ How to enable DHCP routing on Compute Nodes:
To enable routing, update the primary_dns and secondary_dns in provision_config.yml with the appropriate IPs (hostnames are currently not supported). For compute nodes that are not directly connected to the internet (ie only host network is configured), this configuration allows for internet connectivity.
⦾ What to do if the LC is not ready:
Verify that the LC is in a ready state for all servers:
racadm getremoteservicesstatusPXE boot the target server.
⦾ Why does the task: ‘Orchestrator: Deploy MetalLB IP Address pool’ fail?

Potential Cause: /var partition is full (potentially due to images not being cleared after intel-oneapi images docker images are used to execute benchmarks on the cluster using apptainer support) .
Resolution: Clear the /var partition and retry telemetry.yml.
⦾ Why does the task: [Telemetry]: TASK [grafana : Wait for grafana pod to come to ready state] fail with a timeout error?
Potential Cause: Docker pull limit exceeded.
Resolution: Manually input the username and password to your docker account on the control plane.
⦾ Is Disabling 2FA supported by Omnia?
Disabling 2FA is not supported by Omnia and must be manually disabled.
⦾ Is provisioning servers using BOSS controller supported by Omnia?
Provisioning server using BOSS controller is now supported by Omnia 1.2.1.
⦾ How many IPs are required within the PXE NIC range?
Ensure that the number of IPs available between pxe_nic_start_range and pxe_nic_end_range is double the number of iDRACs available to account for potential stale entries in the mapping DB.
⦾ What are the licenses required when deploying a cluster through Omnia?
While Omnia playbooks are licensed by Apache 2.0, Omnia deploys multiple softwares that are licensed separately by their respective developer communities. For a comprehensive list of software and their licenses, click here .
If you have any feedback about Omnia documentation, please reach out at omnia.readme@dell.com.